Remote Device Programming¶
ROCmRDMA¶
ROCmRDMA is the solution designed to allow third-party kernel drivers to utilize DMA access to the GPU memory. It allows direct path for data exchange (peer-to-peer) using the standard features of PCI Express.
Currently ROCmRDMA provides the following benefits:
Direct access to ROCm memory for 3rd party PCIe devices
Support for PeerDirect(c) interface to offloads the CPU when dealing with ROCm memory for RDMA network stacks;
Restrictions and limitations¶
To fully utilize ROCmRDMA the number of limitation could apply impacting either performance or functionality in the whole:
It is recommended that devices utilizing ROCmRDMA share the same upstream PCI Express root complex. Such limitation depends on PCIe chipset manufacturses and outside of GPU controls;
To provide peer-to-peer DMA access all GPU local memory must be exposed via PCI memory BARs (so called large-BAR configuration);
It is recommended to have IOMMU support disabled or configured in pass-through mode due to limitation in Linux kernel to support local PCIe device memory for any form transition others then 1:1 mapping.
ROCmRDMA interface specification¶
The implementation of ROCmRDMA interface could be found in [amd_rdma.h] file.
Data structures¶
/**
* Structure describing information needed to P2P access from another device
* to specific location of GPU memory
*/
struct amd_p2p_info {
uint64_t va; /**< Specify user virt. address
* which this page table described
*/
uint64_t size; /**< Specify total size of
* allocation
*/
struct pid *pid; /**< Specify process pid to which
* virtual address belongs
*/
struct sg_table *pages; /**< Specify DMA/Bus addresses */
void *priv; /**< Pointer set by AMD kernel
* driver
*/
};
/**
* Structure providing function pointers to support rdma/p2p requirements.
* to specific location of GPU memory
*/
struct amd_rdma_interface {
int (*get_pages)(uint64_t address, uint64_t length, struct pid *pid,
struct amd_p2p_info **amd_p2p_data,
void (*free_callback)(void *client_priv),
void *client_priv);
int (*put_pages)(struct amd_p2p_info **amd_p2p_data);
int (*is_gpu_address)(uint64_t address, struct pid *pid);
int (*get_page_size)(uint64_t address, uint64_t length, struct pid *pid,
unsigned long *page_size);
};
The function to query ROCmRDMA interface¶
/**
* amdkfd_query_rdma_interface - Return interface (function pointers table) for
* rdma interface
*
*
* \param interace - OUT: Pointer to interface
* \return 0 if operation was successful.
*/
int amdkfd_query_rdma_interface(const struct amd_rdma_interface **rdma);
The function to query ROCmRDMA interface¶
/**
* amdkfd_query_rdma_interface - Return interface (function pointers table) for rdma interface
* \param interace - OUT: Pointer to interface
* \return 0 if operation was successful.
*/
int amdkfd_query_rdma_interface(const struct amd_rdma_interface **rdma);
ROCmRDMA interface functions description¶
/**
* This function makes the pages underlying a range of GPU virtual memory
* accessible for DMA operations from another PCIe device
*
* \param address - The start address in the Unified Virtual Address
* space in the specified process
* \param length - The length of requested mapping
* \param pid - Pointer to structure pid to which address belongs.
* Could be NULL for current process address space.
* \param p2p_data - On return: Pointer to structure describing
* underlying pages/locations
* \param free_callback - Pointer to callback which will be called when access
* to such memory must be stopped immediately: Memory
* was freed, GECC events, etc.
* Client should immediately stop any transfer
* operations and returned as soon as possible.
* After return all resources associated with address
* will be release and no access will be allowed.
* \param client_priv - Pointer to be passed as parameter on
* 'free_callback;
*
* \return 0 if operation was successful
*/
int get_pages(uint64_t address, uint64_t length, struct pid *pid,
struct amd_p2p_info **amd_p2p_data,
void (*free_callback)(void *client_priv),
void *client_priv);
/**
* This function release resources previously allocated by get_pages() call.
* \param p_p2p_data - A pointer to pointer to amd_p2p_info entries
* allocated by get_pages() call.
* \return 0 if operation was successful
*/
int put_pages(struct amd_p2p_info **p_p2p_data)
/**
* Check if given address belongs to GPU address space.
* \param address - Address to check
* \param pid - Process to which given address belongs.
* Could be NULL if current one.
* \return 0 - This is not GPU address managed by AMD driver
* 1 - This is GPU address managed by AMD driver
*/
int is_gpu_address(uint64_t address, struct pid *pid);
UCX¶
Introduction¶
UCX Quick start¶
Compiling UCX
% ./autogen.sh
% ./contrib/configure-release --prefix=$PWD/install
% make -j8 install
UCX API usage examples¶
Running UCX¶
UCX internal performance tests¶
This infrastructure provided a function which runs a performance test (in the current thread) on UCX communication APIs. The purpose is to allow a developer make optimizations to the code and immediately test their effects. The infrastructure provides both an API, and a standalone tool which uses that API - ucx_perftest. The API is also used for unit tests. Location: src/tools/perf
Features of the library:
uct_perf_test_run() is the function which runs the test. (currently only UCT API is supported)
No need to do any resource allocation - just pass the testing parameters to the API
Requires running the function on 2 threads/processes/nodes - by passing RTE callbacks which are used to bootstrap the connections.
Two testing modes - ping-pong and unidirectional stream (TBD bi-directional stream)
Configurabe message size, and data layout (short/bcopy/zcopy)
Supports: warmup cycles, unlimited iterations.
UCT Active-messages stream is measured with simple flow-control.
Tests driver is written in C++ (C linkage), to take advantage of templates.
- Results are reported to callback function at the specified intervals, and also returned from the API call.
Including: latency, message rate, bandwidth - iteration average, and overall average.
Features of ucx_perftest:
Have pre-defined list of tests which are valid combinations of operation and testing mode.
Can be run either as client-server application, as MPI application, or using libRTE.
Supports: CSV output, numeric formatting.
- Supports “batch mode” - write the lists of tests to run to a text file (see example in contrib/perf) and run them one after another. Every line is the list of arguments that the tool would normally read as command-line options. They are “appended” to the other command-line arguments, if such were passed.
“Cartesian” mode: if several batch files are specified, all possible combinations are executed!
$ ucx_perftest -h
Usage: ucx_perftest [ server-hostname ] [ options ]
This test can be also launched as an MPI application
Common options:
Test options:
-t <test> Test to run.
am_lat : active message latency.
put_lat : put latency.
add_lat : atomic add latency.
get : get latency / bandwidth / message rate.
fadd : atomic fetch-and-add latency / message rate.
swap : atomic swap latency / message rate.
cswap : atomic compare-and-swap latency / message rate.
am_bw : active message bandwidth / message rate.
put_bw : put bandwidth / message rate.
add_mr : atomic add message rate.
-D <layout> Data layout.
short : Use short messages API (cannot used for get).
bcopy : Use copy-out API (cannot used for atomics).
zcopy : Use zero-copy API (cannot used for atomics).
-d <device> Device to use for testing.
-x <tl> Transport to use for testing.
-c <cpu> Set affinity to this CPU. (off)
-n <iters> Number of iterations to run. (1000000)
-s <size> Message size. (8)
-H <size> AM Header size. (8)
-w <iters> Number of warm-up iterations. (10000)
-W <count> Flow control window size, for active messages. (128)
-O <count> Maximal number of uncompleted outstanding sends. (1)
-N Use numeric formatting - thousands separator.
-f Print only final numbers.
-v Print CSV-formatted output.
-p <port> TCP port to use for data exchange. (13337)
-b <batchfile> Batch mode. Read and execute tests from a file.
Every line of the file is a test to run. The first word is the
test name, and the rest are command-line arguments for the test.
-h Show this help message.
Server options:
-l Accept clients in an infinite loop
Example - using mpi as a launcher
When using mpi as the launcher to run ucx_perftest, please make sure that your ucx library was configured with mpi. Add the following to your configure line:
--with-mpi=/path/to/mpi/home
$salloc -N2 --ntasks-per-node=1 mpirun --bind-to core --display-map ucx_perftest -d mlx5_1:1 \
-x rc_mlx5 -t put_lat
salloc: Granted job allocation 6991
salloc: Waiting for resource configuration
salloc: Nodes clx-orion-[001-002] are ready for job
Data for JOB [62403,1] offset 0
======================== JOB MAP ========================
Data for node: clx-orion-001 Num slots: 1 Max slots: 0 Num procs: 1
Process OMPI jobid: [62403,1] App: 0 Process rank: 0
Data for node: clx-orion-002 Num slots: 1 Max slots: 0 Num procs: 1
Process OMPI jobid: [62403,1] App: 0 Process rank: 1
=============================================================
+--------------+-----------------------------+---------------------+-----------------------+
| | latency (usec) | bandwidth (MB/s) | message rate (msg/s) |
+--------------+---------+---------+---------+----------+----------+-----------+-----------+
| # iterations | typical | average | overall | average | overall | average | overall |
+--------------+---------+---------+---------+----------+----------+-----------+-----------+
586527 0.845 0.852 0.852 4.47 4.47 586527 586527
1000000 0.844 0.848 0.851 4.50 4.48 589339 587686
OpenMPI and OpenSHMEM with UCX¶
UCX installation
Requirements: Autoconf 2.63 and above.
1. Get latest version of the UCX code
$ git clone https://github.com/openucx/ucx.git ucx
$ cd ucx
2. Run autogen:
$ ./autogen.sh
3. This step is only required for OpenPOWER platforms - Power 8 On Ubuntu platform the config.guess file is a bit outdated and does not have support for power. In order to resolve the issue you have to download an updated config.guess. From the root of the project:
$ wget https://github.com/shamisp/ucx/raw/topic/power8-config/config.guess
4. Configure:
$ mkdir build
$ cd build
$ ../configure --prefix=/your_install_path
Note
For best performance configuration, use ../contrib/configure-release. This will strip all debugging and profiling code.
5. Build and install:
$ make
$ make install
Running unit tests (using google test). This only work if gtest was installed and detected on your platform, and –enable-gtest was passed to configure:
$ make -C test/gtest test
Interface to ROCm¶
Documentation¶
High Level Design¶
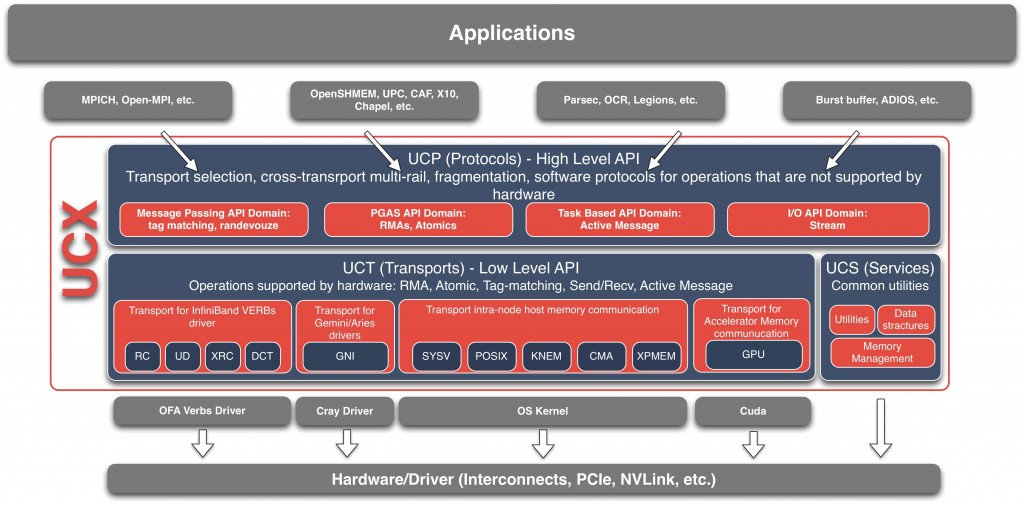
UCX code consists of 3 parts:
Protocol Layer - UCPTransport Layer - UCTServices - UCS
Protocol Layer
Supports all functionality described in the API, and does not require knowledge of particular hardware. It would try to provide best “out-of-box” performance, combining different hardware mechanisms and transports. It may emulate features which are not directly supported in hardware, such as one-sided operations. In addition, it would support common software protocols which are not implemented in hardware, such as tag matching and generic active messages. More details UCP Design
Transport Layer
Provides direct access to hardware capabilities, without decision logic which would prefer one hardware mechanism over another. Some functionality may not be supported, due to hardware limitations. The capabilities are exposed in the interface. More details UCT Design
Services
Collection of generic services, data structures, debug aids, etc.
Responsibilities of each layer
What |
Where |
Why |
|---|---|---|
Tag matching |
High level |
Software protocol |
RMA/AMO emulation |
High level |
Software protocol |
Fragmentation |
High level |
Software protocol |
Pending queue |
High level |
Stateful |
Multi-transport/channel/rail |
High level |
OOB optimization |
Select inline/bcopy/zcopy |
High level |
optimization logic |
Reliability (e.g UD) |
Low level |
Transport specific |
DMA buffer ownership |
Low level |
Transport specific |
Memory registration cache |
Low level |
Transport dependent |
See also:
Infrastructure and Tools¶
Tools
Infrastructure library (UCS)
Configuration parsing
- Data structures:
Double linked list
Single linked queue
Fragment list - reordering
Memory pool
Index/Pointer array
- Fast time measurement
Read CPU timer
Convert time to sec/msec/usec/nsec
Timer queue
Timer wheel
- Data types:
Callback
Class infrastructure
Component infrastructure
Spinlock
Error codes
- System services:
Atomic operations
Fast bit operations (find first set bit, integer log2)
Get hostname
Generate UUID
Get CPU affinity
Read a whole file
Get page / huge page size
Allocate memory with SystemV
Get memory region access flags (from /proc/$$/maps)
Modify file flags with fcntl
Get process command line
Get CPU model, clock frequency
Get thread ID
FAQ¶
What is UCX ?
UCX is a framework (collection of libraries and interfaces) that provides efficient and relatively easy way to construct widely used HPC protocols: MPI tag matching, RMA operations, randevouze protocols, stream, fragmentation, remote atomic operations, etc.
How do I get in touch with UCX developers ?
Please join our mailing list: https://elist.ornl.gov/mailman/listinfo/ucx-group
What is UCP, UCT, UCS
UCT is a transport layer that abstracts the differences across various hardware architectures and provides a low-level API that enables the implementation of communication protocols. The primary goal of the layer is to provide direct and efficient access to hardware network resources with minimal software overhead. For this purpose UCT relies on low-level drivers provided by vendors such as InfiniBand Verbs, Cray’s uGNI, libfabrics, etc. In addition, the layer provides constructs for communication context management (thread-based and ap- plication level), and allocation and management of device- specific memories including those found in accelerators. In terms of communication APIs, UCT defines interfaces for immediate (short), buffered copy-and-send (bcopy), and zero- copy (zcopy) communication operations. The short operations are optimized for small messages that can be posted and completed in place. The bcopy operations are optimized for medium size messages that are typically sent through a so- called bouncing-buffer. Finally, the zcopy operations expose zero-copy memory-to-memory communication semantics.
UCP implements higher-level protocols that are typically used by message passing (MPI) and PGAS programming models by using lower-level capabilities exposed through the UCT layer. UCP is responsible for the following functionality: initialization of the library, selection of transports for communication, message fragmentation, and multi-rail communication. Currently, the API has the following classes of interfaces: Initialization, Remote Memory Access (RMA) communication, Atomic Memory Operations (AMO), Active Message, Tag-Matching, and Collectives.
UCS is a service layer that provides the necessary func- tionality for implementing portable and efficient utilities.
What are the key features of UCX ?
Open source framework supported by vendors The UCX framework is maintained and supported by hardware vendors in addition to the open source community. Every pull-request is tested and multiple hardware platforms supported by vendors community.
Performance, performance, performance… The framework design, data structures, and components are design to provide highly optimized access to the network hardware.
High level API for a broad range HPC programming models. UCX provides a high level API implemented in software ‘UCP’ to fill in the gaps across interconnects. This allows to use a single set of APIs in a library to implement multiple interconnects. This reduces the level of complexities when implementing libraries such as Open MPI or OpenSHMEM. Because of this, UCX performance portable because a single implementation (in Open MPI or OpenSHMEM) will work efficiently on multiple interconnects. (e.g. uGNI, Verbs, libfabrics, etc).
Support for interaction between multiple transports (or providers) to deliver messages. For example, UCX has the logic (in UCP) to make ‘GPUDirect’, IB’ and share memory work together efficiently to deliver the data where is needed without the user dealing with this.
Cross-transport multi-rail capabilities
What protocols are supported by UCX ?
UCP implements RMA put/get, send/receive with tag matching, Active messages, atomic operations. In near future we plan to add support for commonly used collective operations.
Is UCX replacement for GASNET ?
No. GASNET exposes high level API for PGAS programming management that provides symmetric memory management capabilities and build in runtime environments. These capabilities are out of scope of UCX project. Instead, GASNET can leverage UCX framework for fast end efficient implementation of GASNET for the network technologies support by UCX.
What is the relation between UCX and network drivers ?
UCX framework does not provide drivers, instead it relies on the drivers provided by vendors. Currently we use: OFA VERBs, Cray’s UGNI, NVIDIA CUDA.
What is the relation between UCX and OFA Verbs or Libfabrics ?
UCX, is a middleware communication layer that relies on vendors provided user level drivers including OFA Verbs or libfabrics (or any other drivers provided by another communities or vendors) to implement high-level protocols which can be used to close functionality gaps between various vendors drivers including various libfabrics providers: coordination across various drivers, multi-rail capabilities, software based RMA, AMOs, tag-matching for transports and drivers that do not support such capabilities natively.
Is UCX a user level driver ?
No. Typically, Drivers aim to expose fine-grain access to the network architecture specific features. UCX abstracts the differences across various drivers and fill-in the gaps using software protocols for some of the architectures that don’t provide hardware level support for all the operations.
Does UCX depend on an external runtime environment ?
UCX does not depend on an external runtime environment.
ucx_perftest (UCX based application/benchmark) can be linked with an external runtime environment that can be used for remote ucx_perftest launch, but this an optional configuration which is only used for environments that do not provide direct access to compute nodes. By default this option is disabled.
How to install UCX and OpenMPI ?
See How to install UCX and OpenMPI
How can I contribute ?
1.Fork2.Fix bug or implement a new feature3.Open Pull Request
MPI¶
OpenMPI and OpenSHMEM installation
1. Get latest-and-gratest OpenMPI version:
$ git clone https://github.com/open-mpi/ompi.git
2. Autogen:
$ cd ompi
$ ./autogen.pl
3. Configure with UCX
$ mkdir build
$ cd build
../configure --prefix=/your_install_path/ --with-ucx=/path_to_ucx_installation
4. Build:
$ make
$ make install
Running Open MPI with UCX
Example of the command line (for InfiniBand RC + shared memory):
$ mpirun -np 2 -mca pml ucx -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_TLS=rc,sm ./app
Open MPI runtime optimizations for UCX
By default OpenMPI enables build-in transports (BTLs), which may result in additional software overheads in the OpenMPI progress function. In order to workaround this issue you may try to disable certain BTLs.
$ mpirun -np 2 -mca pml ucx --mca btl ^vader,tcp,openib -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_TLS=rc,sm ./app
OpenMPI version https://github.com/open-mpi/ompi/commit/066370202dcad8e302f2baf8921e9efd0f1f7dfc leverages more efficient timer mechanism and there fore reduces software overheads in OpenMPI progress
MPI and OpenSHMEM release versions tested with UCX master
UCX current tarball: https://github.com/openucx/ucx/archive/master.zip
The table of MPI and OpenSHMEM distributions that are tested with the HEAD of UCX master
MPI/OpenSHMEM |
project |
OpenMPI/OSHMEM |
2.1.0 |
MPICH |
Latest |
IPC¶
Introduction¶
New datatypes
hsa_amd_ipc_memory_handle_t
/** IPC memory handle to by passed from one process to another */
typedef struct hsa_amd_ipc_memory_handle_s {
uint64_t handle;
} hsa_amd_ipc_memory_handle_t;
hsa_amd_ipc_signal_handle_t
/** IPC signal handle to by passed from one process to another */
typedef struct hsa_amd_ipc_signal_handle_s {
uint64_t handle;
} hsa_amd_ipc_signal_handle_t;
Memory sharing API
Allows sharing of HSA allocated memory between different processes.
hsa_status_t HSA_API
hsa_status_t HSA_API
hsa_status_t HSA_API
Signal sharing API
hsa_status_t HSA_API
hsa_status_t HSA_API
hsa_status_t HSA_API
Client should call hsa_signal_destroy() when access to this resource is not needed any more.
Query API
Allows query information about memory resource based on address. It is partially overlapped with the following requirement Memory info interface so it may be possible to merge those two interfaces.
typedef enum hsa_amd_address_info_s {
/* Return uint32_t / boolean if address was allocated via HSA stack */
HSA_AMD_ADDRESS_HSA_ALLOCATED = 0x1,
/** Return agent where such memory was allocated */
HSA_AMD_ADDRESS_AGENT = 0x2,
/** Return pool from which this address was allocated */
HSA_AMD_ADDRESS_POOL = 0x3,
/** Return size of allocation */
HSA_AMD_ADDRESS_ALLOC_SIZE = 0x4
} hsa_amd_address_info_t;
hsa_status_t HSA_API